
NEW CASES IN LAST 30 DAYS
Poultry: 1,854,360 UP: 2.09%
Wildbird: 109 UP: 2.72%
Diary Cow Herds: 19 UP: 1.9%
TOTAL CASES SINCE 2024-01-01
Poultry: 88,581,770.00 cases.
Wildbird 4,001.00 cases.
Dairy Cow 998.00 herds.
Updates since my last report on 2025_03_28:
ESTABLISHMENTS
There are 1 more Egg processing establishments within counties reporting Poultry H5N1 cases. 17 out of 47 (36.17%) FSIS inspected Egg establishments are in infected counties.
There are 1 more Poultry Slaughter establishments within counties reporting Poultry H5N1 cases. 89 out of 426 (20.89%) FSIS inspected Poultry Slaughter establishments are in infected counties.
2 at risk Poultry establishments became infected from Wildbrid/Mammal spreading of Avian Flu.
At risk Egg establishments grew by 0 thanks to Wildbrid/Mammal spreading of Avian Flu.
STATES & COUNTIES
Counties with Poultry cases increased by 2 for a total of 317 affected counties since 01/01/2024
Counties with Wildbird cases stayed flat with 0 new counties, total affected sits at 524
States with Dairy Cow Herds stayed flat with 0 new states, total affected sits at 18
Avian Flu: 03/11/2025
NEW CASES IN LAST 30 DAYS
Poultry: 7,940,820 UP: 9.18%
Wildbird: 280 UP: 7.39%
Diarycow Herds: 19 UP: 1.93%
TOTAL CASES SINCE 2024-01-01
Poultry: 86,497,926.00 cases.
Wildbird 3,791.00 cases.
DairyCow 985.00 cases.
STATES & COUNTIES
Counties with Poultry cases increased by 23 for a total of 296 affected counties since 01/01/2024
Counties with Wildbird cases increased by 17 for a total of 517 affected counties since 01/01/2024
States with DairyCow Herds stayed flat with 0 new states, total affected sits at 18
What about Eggs?
The effect of Avian Influenza on Eggs is hard to nail down as Egg production forecasts are not a guarantee. In order to get insight into this sector we will have to make some assumptions and use averages when creating forecast formulas.
According to the USDA: "There is no treatment for HPAI. The only way to stop the disease is to depopulate all affected and exposed poultry." Meaning, it is presumed that any reported Poultry case has resulted in a death/culling.
Egg Layer is outpacing Broiler with infection cases: 68,402,500 to 8,739,850
Egg Layer makes up 79.08% of all Poultry cases while Broiler makes up just 10.1%
Pullets (future Egg Layers) are currenting tracking at 3.07%
TLDR, whats the situation today?:
Assuming most growers are attempting to replace all bird losses and increase their population to the three-year median level, my model estimates the Breeder Stock population in the US is sitting around 3,807,110 a decrease of 82,889 from 3,890,000 in Jan 2024.
The same model suggests Table Egg Layer population is currently at 307,075,251 a decrease of 12,924,749 from 320,000,000 in Jan 2024.
Taking a look at last week: 6,365,346 (33.04%) Breeder Stock eggs were used to replenish lost Breeders and Table Egg Layers instead of going to other uses such as Retail and Live sales.
Table Egg Layers laid 1,867,647,277 Eggs, 5.0% short if there were no Avian flu deaths, just 97.22% of their production if a median bird population was kept.
A total of 0 Table Eggs were lost this week. 22,525,172 so far in 2025.
Terms:
1. Table Egg Layers are birds that lay Eggs meant for retail/further processing.
2. Breeder Stock Hens are birds breed to produce fertilized eggs that hatch into Table Egg Layers. If their numbers decline, so does the future population of Table Egg Layers and therefore the inventory of Retail Eggs.
3. Pullets are Chicks that haven’t matured into Table Egg Layers yet.
Limited Data: The USDA does not currently report Avian Flu cases for Breeder Stock Hens. However, Breeder stock Hens make up 1.21% of birds related to Table Egg Laying. So we will calculate their exposure to Avian Flu using that percentage against all Table Egg Layers reported on the Avian Flu numbers.
Assumptions, Averages and Medians:
1. For 2022-2024 the Median number of Table Egg Layers was 315,963,300 with Breeding Stock at 3,840,480. They make up 98.79% and 1.21% of the Egg laying population respectively. These are the population numbers we will attempt to maintain.
2. Per the USDA, in December 2023 the Breeder Stock population was 3.89 Million and the Table Egg Layer population was 320 Million. We will start with these numbers.
3. Per the USDA, for every 100 Egg Layers there is an average of 80 Eggs laid daily.
4. Let’s assume there is a 60% replacement rate each year due to old age, declining productivity and other natural causes (not Avian Flu). Meaning, 60% of the years starting population will need to be replaced by year end.
5. Assume an 85% Hatchability rate for all Eggs.
6. 50% chance of either Male or Female Chick for all Eggs.
7. Chick survival rate of 90%.
8. Pullets/Chicks take 18 weeks (126 Days) to Mature into Egg laying Hens.
Formulas:
Without getting too complicated.
We have two running populations: Breeder Stock and Table Layers. Each day we subtract their respective share of the Avian Flu deaths and the annual 60% replacements. [(Population * 60%)/365] We then add the matured Pullet population minus any Pullet Avian Flu deaths.
Breeder Stock Egg production is determined by a quick formula outlined above. 80 Eggs for every 100 layers, 93% chance of Fertilization and 85% Hatchability. [(((Population/100)*80)*93%)*85%)
Table Egg Layer Egg production is determined slightly differently. 80 Eggs for every 100 layers and a 95% chance the Egg is usable. This allows 5% uncertainty for accidents/issues.
Eggs to Pullets are estimated by adding up several variables. Birds needing replacements, Avian Flu Deaths, and median population refill. These are subtracted from the Breeder Stock Egg Production and held onto for 18 weeks to mature.
Avian Flu: 03/07/2025
NEW CASES IN LAST 30 DAYS
Poultry: 9,555,030 UP: 11.02%
Wild bird: 249 UP: 6.64%
Diary cow Herds: 16 UP: 1.63%
TOTAL CASES SINCE 2024-01-01
Poultry: 86,703,144.00 cases.
Wildbird 3,748.00 cases.
DairyCow 980.00 cases.
Updates since my last report on 2025-02-19:
ESTABLISHMENTS
There are 1 more Egg processing establishments within counties reporting Poultry H5N1 cases. 16 out of 47 (34.04%) FSIS inspected Egg establishments are in infected counties.
There are 3 more Poultry Slaughter establishments within counties reporting Poultry H5N1 cases. 86 out of 426 (20.19%) FSIS inspected Poultry Slaughter establishments are in infected counties.
9 at risk Poultry establishments became infected from Wildbrid/Mammal spreading of Avian Flu.
At risk Egg establishments grew by 0 thanks to Wildbrid/Mammal spreading of Avian Flu.
STATES & COUNTIES
Counties with Poultry cases increased by 18 for a total of 291 affected counties since 01/01/2024
Counties with Wildbird cases increased by 10 for a total of 510 affected counties since 01/01/2024
States with DairyCow Herds stayed flat with 0 new states, total affected sits at 18
Below is a map of counties in the USA where H5N1 has been reported in various Poultry.
The state with the most NEW cases within the last 7 reporting days is: Indiana with a reported count of: 228,030
The state with the most overall reported Poultry cases is: California with a total count of: 18,217,528


What about Eggs?
The effect of Avian Influenza on Eggs is hard to nail down as Egg production forecasts are not a guarantee. In order to get insight into this sector we will have to make some assumptions and use averages when creating forecast formulas.
According to the USDA: "There is no treatment for HPAI. The only way to stop the disease is to depopulate all affected and exposed poultry." Meaning, it is presumed that any reported Poultry case has resulted in a death/culling.
Egg Layer is outpacing Broiler with infection cases: 68,647,800 to 8,739,850
Egg Layer makes up 79.18% of all Poultry cases while Broiler makes up just 10.08%
Pullets (future Egg Layers) are currenting tracking at 3.06%
TLDR, what’s the situation today?
Assuming most growers are attempting to replace all bird losses and increase their population to the three-year median level, my model estimates the Breeder Stock population in the US is sitting around 3,805,851 a decrease of 84,149 from 3,890,000 in Jan 2024.
The same model suggests Table Egg Layer population is currently at 306,972,361 a decrease of 13,027,639 from 320,000,000 in Jan 2024.
Taking a look at last week: 6,559,114 (34.05%) Breeder Stock eggs were used to replenish lost Breeders and Table Egg Layers instead of going to other uses such as Retail and Live sales.
Table Egg Layers laid 1,867,494,568 Eggs, 5.01% short if there were no Avian flu deaths, just 97.21% of their production if a median bird population was kept.
A total of 140,550 Table Eggs were lost this week. 22,709,344 so far in 2025.
Terms:
1. Table Egg Layers are birds that lay Eggs meant for retail/further processing.
2. Breeder Stock Hens are birds breed to produce fertilized eggs that hatch into Table Egg Layers. If their numbers decline, so does the future population of Table Egg Layers and therefore the inventory of Retail Eggs.
3. Pullets are Chicks that haven’t matured into Table Egg Layers yet.
Limited Data: The USDA does not currently report Avian Flu cases for Breeder Stock Hens. However, Breeder stock Hens make up 1.21% of birds related to Table Egg Laying. So we will calculate their exposure to Avian Flu using that percentage against all Table Egg Layers reported on the Avian Flu numbers.
Assumptions, Averages and Medians:
1. For 2022-2024 the Median number of Table Egg Layers was 315,963,300 with Breeding Stock at 3,840,480. They make up 98.79% and 1.21% of the Egg laying population respectively. These are the population numbers we will attempt to maintain.
2. Per the USDA, in December 2023 the Breeder Stock population was 3.89 Million and the Table Egg Layer population was 320 Million. We will start with these numbers.
3. Per the USDA, for every 100 Egg Layers there is an average of 80 Eggs laid daily.
4. Let’s assume there is a 60% replacement rate each year due to old age, declining productivity and other natural causes (not Avian Flu). Meaning, 60% of the years starting population will need to be replaced by year end.
5. Assume an 85% Hatchability rate for all Eggs.
6. 50% chance of either Male or Female Chick for all Eggs.
7. Chick survival rate of 90%.
8. Pullets/Chicks take 18 weeks (126 Days) to Mature into Egg laying Hens.
Formulas:
Without getting too complicated.
We have two running populations: Breeder Stock and Table Layers. Each day we subtract their respective share of the Avian Flu deaths and the annual 60% replacements. [(Population * 60%)/365] We then add the matured Pullet population minus any Pullet Avian Flu deaths.
Breeder Stock Egg production is determined by a quick formula outlined above. 80 Eggs for every 100 layers, 93% chance of Fertilization and 85% Hatchability. [(((Population/100)*80)*93%)*85%)
Table Egg Layer Egg production is determined slightly differently. 80 Eggs for every 100 layers and a 95% chance the Egg is usable. This allows 5% uncertainty for accidents/issues.
Eggs to Pullets are estimated by adding up several variables. Birds needing replacements, Avian Flu Deaths, and median population refill. These are subtracted from the Breeder Stock Egg Production and held onto for 18 weeks to mature.
To give you an idea of how these outbreaks affect/relate to Poultry and Egg operations in the US, here is the heat map with Poultry and Egg Operations over layed on top.

The USDA also tracks Wildbirds which are big carries of the disease.


Avian Flu is predominately spread via Wildbirds from one Poultry flock to another. However, there has also been quite a few cases detected in other Mammals that can easily spread the disease.
These other Mammals include small roddents, house cats, domesticated dogs, wolves, deer, etc.
There are currently 12 Poultry operations and 1 Egg opertaions residing in counties with Wildbird/Mammal cases but no reported Poultry cases.
These operations are at risk of being exposed to outbreaks.
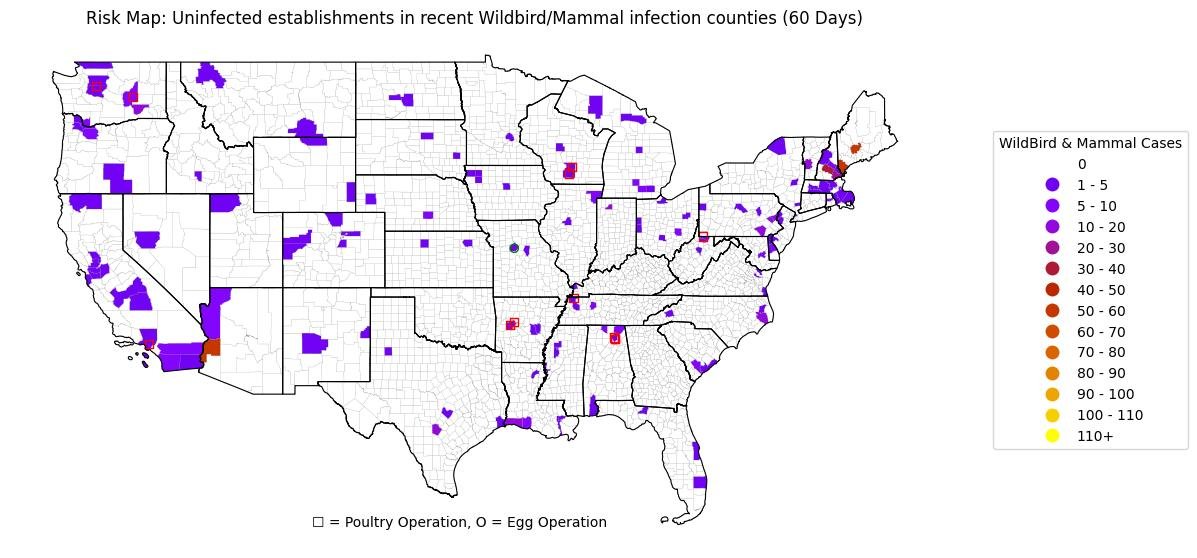
Lastly, there has been a significant amount of cases in Dairy Cows all across the United States.


Correction: More Gloom than Doom
I did some more research and came up with a much more complicated but focused formula. Instead of using 18 week cycles, which leaves plenty of room for missed variables, I decided to view the problem week by week.
The good news: the Egg layer population isn’t crashing out.
The bad news: previously available for retail eggs are being used to replenish egg layer populations.
TLDR, what’s the situation today?
Assuming most growers are attempting to replace all bird losses and increase their population to the three-year median level, my model estimates the Breeder Stock population in the US is sitting around 3,774,627 a decrease of 5,373 from 3,780,000 in Jan 2024.
The same model suggests Table Egg Layer population is currently at 302,954,162 a decrease of 8,045,838 from 311,000,000 in Jan 2024.
Taking a look at last week: 7,505,025 (39.22%) Breeder Stock eggs were used to replenish lost Breeders and Table Egg Layers instead of going to other uses such as Retail and Live sales.
Table Egg Layers laid 1,846,019,083 Eggs, 5.12% short if there were no Avian flu deaths, just 96.09% of their production if a median bird population was kept.
A total of 2,383,952 Table Eggs were lost this week. 22,501,221 so far in 2025.
Terms
Table Egg Layers are birds that lay Eggs meant for retail/further processing.
Breeder Stock Hens are birds breed to produce fertilized eggs that hatch into Table Egg Layers. If their numbers decline, so does the future population of Table Egg Layers and therefore the inventory of Retail Eggs.
Pullets are Chicks that haven’t matured into Table Egg Layers yet.
Limited Data
The USDA does not currently report Avian Flu cases for Breeder Stock Hens. However, Breeder stock Hens make up 1.21% of birds related to Table Egg Laying. So we will calculate their exposure to Avian Flu using that percentage against all Table Egg Layers reported on the Avian Flu numbers.
Assumptions, Averages and Medians
For 2022-2024 the Median number of Table Egg Layers was 315,963,300 with Breeding Stock at 3,840,480. They make up 98.79% and 1.21% of the Egg laying population respectively. These are the population numbers we will start at and attempt to maintain.
Per the USDA, for every 100 Egg Layers there is an average of 80 Eggs laid daily.
Let’s assume there is a 60% replacement rate each year due to old age, declining productivity and other natural causes (not Avian Flu). Meaning, 60% of the years starting population will need to be replaced by year end.
Assume an 85% Hatchability rate for all Eggs.
50% chance of either Male or Female Chick for all Eggs.
Chick survival rate of 90%.
Pullets/Chicks take 18 weeks (126 Days) to Mature into Egg laying Hens.
Formulas
Without getting too complicated.
We have two running populations: Breeder Stock and Table Layers. Each day we subtract their respective share of the Avian Flu deaths and the annual 60% replacements. [(Population * 60%)/365] We then add the matured Pullet population minus any Pullet Avian Flu deaths.
Breeder Stock Egg production is determined by a quick formula outlined above. 80 Eggs for every 100 layers, 93% chance of Fertilization and 85% Hatchability. [(((Population/100)*80)*93%)*85%)
Table Egg Layer Egg production is determined slightly differently. 80 Eggs for every 100 layers and a 95% chance the Egg is usable. This allows 5% uncertainty for accidents/issues.
Eggs to Pullets are estimated by adding up several variables. Birds needing replacements, Avian Flu Deaths, and median population refill. These are subtracted from the Breeder Stock Egg Production and held onto for 18 weeks to mature.
Replenishing lost Eggs: Some quick and dirty math
A scary quote
USDA: "There is no treatment for HPAI. The only way to stop the disease is to depopulate all affected and exposed poultry."
Meaning, it is presumed that any reported Poultry case has resulted in a death/culling.
Egg Layer is outpacing Broiler (raised for meat) with infection cases: 65,029,900 to 8,739,850
Egg Layer makes up 78.43% of all Poultry cases while Broiler makes up just 10.54%
Pullets (future Egg Layers) are currenting tracking at 3.2%
Well how many Egg Layers can we lose?
Per the USDA: as of January 1, 2024, there were 379 million commercial egg-laying hens in the United States. 1% increase from 2023.
In order to calculate where we are today and what affect Avian Influenza may be having on our flocks, we are going to have to create a formula to fuel a model.
Key Variables
It takes 18 weeks before a Hen will begin to lay eggs. At that point, they can lay an average of 5 eggs a week.
Lets (generously) assume that only 7% of Egg Laying Hens die each year from non-AvianFlu related causes. Every 18 weeks that’s 9,183,461 (Population X ((Annual Death Rate/52) X 18))
And lets assume commercial operations account for the natural deaths and have already planned to replace them with Pullets. Hopefully they are also able to find a way to replace 50% of all birdflu deaths from the previous 18 weeks, example: 21,308,028 ((Previous 18 week Egg Layer AvianFlu Deaths X 50%) + Natural Deaths Replacements)
Formula
(Current Population - (Egg Layer Natural Deaths + Egg Layer AvianFlu Deaths)) + (Replacements - Pullet Deaths)
Using this formula, we should be able to get a rough estimate of the growth/contraction of the Egg Layer population over an 18 week cycle with a quick model.

If my math is correct, on 2025-01-15 the Egg Layer population hit 348,985,150. A decrease of 30,014,850 from 379,000,000 in January 2024.
By only replacing 50% of Avian Influenza deaths and without easing the disease, we are on track to have a further population decrease of 9,422,150 by 2025-05-22.
That’s a nearly 10% population decline in a little less than a year and a half!
The population will not increase unless we are able to treat Avian Influenza instead of culling the infected/exposed.
See the table below to see a breakdown of Poultry type and a count of AvianFlu cases/deaths.

All data used to feed tables, formulas and models come from the USDAs public datasets on the Avian Flu outbreak.
How to post Images with Hashtags on Bluesky using Python
As it turns out, posting to Bluesky (bsky.app) with Python is very easy.
All you need is the atproto library and an app password to your account. 8 lines of code later and you can upload text posts to your account no problem.
from atproto import Client
def main():
client = Client()
client.login(USER, APP_PASS)
client.send_post(text='#AvianFlu')
if __name__ == '__main__':
main()But, what if you want to upload an image? That actually not hard at all either.
BUT, what if you want to upload an image with text that contains an interactable hashtag so that your post shows up on that tags feed? Impossible…..according to Google.
And the BSky development docs are also unclear as to how to approach this with Python. So I had to dig and research and test and re-test. Finally I found what I was looking for with the atproto documentation. Even after that I had to add my own armature spin to the code.
The following code will allow you to create a function and pass it three variables: Text, Image path, Alt text. From there the function will determine if any word in the text you provided needs to be enriched as to become a hashtag or stay as plain text.
This function is currently serving as a way to publicly broadcast my analysis of Avian Flu and its spread through the US food system.
## Import atproto library
from atproto import Client
def bsky_image_post(post_text,image,alt_text):
## Create the client and login with app password
client = Client()
client.login(USER, APP_PASS)
## Call TextBuilder to create a richtext post
text_builder = client_utils.TextBuilder() ## Creates a fresh text_builder object to add to
# Itterate through text to find tags, build out tag for post
for word in post_text.split(' '):
## If words first character is not a hastag
if word[0] != '#':
text_builder.text(word+" ") ## Add word as plain text with a space after
## If word first character is a hastag
if word[0] == '#':
text_builder.tag(word+" ", word.replace('#','')) ## Add word as a tag, tag value must be the word only as the text_builder will add a #
text_builder.text(" ") ## Add a plain text space after to space out the words
## Load Image
with open(image, 'rb') as f:
img_data = f.read()
## Send post to BlueSky
client.send_image(text=text_builder, ## Add Text
image=img_data, ## Add Image
image_alt=alt_text ## Add Image alternative text
)It is alive!
The Bluesky bot lives!
Now with manually pushed Avian Flu data updates. I’ll get to more of this soon.
Notes for future me
Can I use this to get Egg Price data?
https://www.ams.usda.gov/mnreports/ams_3725.pdf
Would Milk testing data be good to add to the other report?
https://www.aphis.usda.gov/livestock-poultry-disease/avian/avian-influenza/hpai-detections/livestock/nmts
Welp...
This might screw up the quality of my data….
HHS official halts CDC reports and health communications for Trump team review
Bird Flu Data Collection: This sucks
So most of the reports and visualization dashboards out there right now are pulling their data from the USDA.
Yet, when you visit the USDA link, their data is hidden behind another visualization object which is usually a map. To access the data feeding the map you have to choose the data from a dropdown and then choose the file format you want to download. The data labels are not always clean and some of the data options are completely empty upon download.
As someone who routinely works with the USDA, none of this surprises me. Their data organization skills are sub-par.
Moving on….
I gathered 6 data points that I want to track/think will give us a good view of the virus spread.
Waste water detections from the CDC.
Human Cases from the CDC.
Poultry Cases the CDC has an easy download link, but they get their data from the USDA.
Wild Bird Cases the CDC has an easy download link, but they get their data from the USDA.
Mammal Cases from the USDA.
Dairy Cow Cases from the USDA.
One other point I will be pulling from is the FSIS Inspected Establishments list and potentially try to gather the state inspected establishments if I can confirm they are poultry. Not all farms/processors are federally inspected, some are done by the state they reside in. The state inspection lists aren’t always as informative as the FSIS ones are.
While the virus specific data points will help me track the actual virus, the FSIS and state lists can help me find potential new outbreak hotspots. For instance, if the biggest outbreaks of the virus are happening in areas with multiple big poultry operations, where else are there multiple bog poultry operations?
Bird Flu
I’m staring at a rabbit hole I know will take me far.
The bird flu interests me on multiple levels.
One: It’s tied to my work seeing as we work with poultry.
Two: It reminds me of the early days of Covid. Lots of numbers being thrown around without any real idea what is happening.
Three: It seems to me, at least on the surface, that this thing could be easily tracked and predictable. To a degree.
On the last part, if birds are getting sick, it would be easy to assume that farms/processing plants dealing with ABF (Anti-Biotic Free) and/or organic poultry may be more susceptible to an outbreak. Therefore, the human and animal populations within the surrounding area have a higher potential of mutation and transmission. So by mapping all these farms and processing plant, we can establish potential human case starting points across the entire US.
Getting all this data together will be a bitch. I think I’ll have to get all the poultry farms and plants by zip code. Then categorize them by type. Then get the reporting data of sick animals and human cases and overlay that data. See if my hunch is correct. From there I can build prediction models and track this thing much like I did with Covid. Oh the good old days….
Unreliable writer...
Clearly I suck at this.
Going forward I have set up calendar events to remind me to do this once a day. Mostly in the morning so I can recap yesterdays discoveries.
NLP MODELS: BUDGET
I was able to update my scripts and models for my personal monthly budget and I am happy to say it only took 75 trainings to get a > 90% model. Nearly all my transactions where labeled properly and fed the budget breakdown instantly. 2025 should be the year of quick budgeting. Which is fantastic considering this monthly task used to take me hours back in 2016.
And to make sure the model can keep learning I implemented a task at the beginning of each run to grab the 75 most recently classified transactions and add them to the training pool for the pre-trained model. The model is then trained again with the added data and used to classify the current months transactions. This ensures that any incorrect classifications from the prior month, after I manually fix them, are added into the models dataset.
An ever learning monthly budgeter.
NLP MODELS: WORK
My goal for the year is to achieve a training dataset of over 75,000 entries. That’s just less than 25,000 new entries from todays starting point. 75,000 entries multiplied by my variance function (AKA the Ponzi Scheme) should net me a training set of more than a million combinations. Elevating the trained models more and more.
The Beginning, a 2025 project
I decided I want to set a goal of writing each weekday of 2025, journaling my process and progress of various projects for the year.
Current WIP (work in progress) projects that are in the air as of today:
NLP Models for work
NLP model for personal budgeting
RPI / Arduino / LiDar Security Car
H5N1 Data Tracking Dashboard (Much like my old Covid tracking)
Beef Cut Desk Mat
Stock picker
CAPM certification
TAD outreach
The first project on the list is the highest on purpose. That project is very important to me.
The budget NLP model will help me save time through out the year as I tally up my monthly spending at the end of every month.
The other projects are some passion projects of mine with the exception of the CAPM certificate. This is a joint venture with my girlfriend as she attempts to further her career.
NLP Model: 12%
Gained a 12% accuracy increase for my problem child category.
Data Cleaning, 800 lines of new training data and 3 additional training runs.
Next I’m going to try introducing custom stop words in an attempt to further the cleaning process.
Update:
Adding the cleaning process decreased the cumulative score of both models by 2 points. I’ll turn that off for now, but I think training a model from scratch, with the cleaner turned on, may actually be the better idea.
NLP Model: Setting up for success
I have 18 categories to classify.
Each category contains anywhere from 3 - 140+ classes.
15 of my categories are routinely scoring 90% and above when back tested. 2 others are scoring between 80-90% and the last is my problem child. The last category is my largest with 140+ classes in it for the model to choose from. This category started at 25%.
PROBLEM 1: DIRTY DATA
One of the first things I noticed were mistakes in the classification for this class. Misspellings or just straight up incorrect class choice. One of the most common misspelling was making a singular item plural.
To combat the multiple potential problems, I created a script to go through every class of each category and compare it to the other classes within it’s own category. It would then return a “similarity score” and return any classes that were over 80% similar. This uncovered all the misspelled and pluralized classes to which I then updated within the dataset.
Fixing these increased accuracy by 5-10%.
PROBLEM 2: VARIANCE
My next problem was dealing with variance in similar classes within one category. For example: 1/4in Hex Bolt is similar to 1/2in Hex Bolt, yet they are two completely different items.
For a time I was attempting to classify both within the same category. With 30 1/4in examples and 42 1/2in examples, compared to other classes with 100+ examples, the model struggled to identify either. That’s when I decided to create a “Sizing” category. Hex Bolt is the “Product” and 1/4in or 1/2in is the size. So now the model has 70 examples of Hex Bolt as a “Product”. And since “Sizing” is only dealing with two classes, it has an easier time identifying them.
I continued this for all other classes that could fit this scenario. Consolidating similar items and separating the various characteristics that I could.
This increased the “Product” accuracy by 15% while “Sizing” came in above 90%.
Now my problem child is coming in at 45% single shot training and nearly 50% on second training.
I think the next thing I need to focus on is the parameters for training.
I’ve already consolidated as much as I can. The only other idea I have is to breakout different models for different item types. Such as all the Bronze items have their own model, Silver has their own. But the computing power for the actual classifying is limited. Having to run 5+ models per classification will take over an hour to do. I want to perform this quicker.
NLP Model: A problem set one year in
I first had the idea for this particular project about three years ago. I'm now a year into the project and I have learned much. Yet I feel like I know nothing.
What is an NLP?
A machine learning technology that enables computers to understand, process, and manipulate human language. NLP is a branch of artificial intelligence, computer science, and linguistics. It uses techniques like machine learning, neural networks, and text mining to interpret language, translate between languages, and recognize patterns. NLP is used in many everyday products and services, including search engines, chatbots, voice-activated digital assistants, and translation apps.
Why an NLP?
I had tried several approaches and tested a few ideas. Ultimately I realized that my raw inputs would be too messy for most models. I needed something flexible and capable of comparing words within a sentence. NLP seemed like the best option that required the least physical resources.
What model am I using?
I am currently using a pre-trained Distilled BERT model that I am fine-tuning with my custom data.
How do I train it?
I will probably get into this with more detail at a later date, mostly because I want to update this part. However, I am converting the training data into a DataFrame with Python and then splitting that data into train and validation sets. But I feel like I can improve this significantly.
Goal
Classify an incredibly large dataset with at least 85% accuracy on an hourly basis without human assistance.
Problems
There are no training datasets for public consumption. I need to create my own.
The dataset needs to be fairly big in order to get the best results.
The custom dataset needs to be classified manually, which takes longer the bigger it is.
There will be over 360 different classes in the dataset. There needs to be a balance.
My processing power is limited to a 6 year old GTX1070
The first couple problems have already been solved/still being solved. I have created 36,000+ lines of training data by scraping data that gets sent directly to me on a daily basis. And also, since I’m a data hoarder, I still have three years worth of raw data to convert into usable training data.
The third problem is still an ongoing problem. It takes a long long time to classify 36,000+ lines of training data. And my plan for the summer is to have 40,000 lines of training data. My next problem is that while I gain good training data for some classes, I’m still lacking for other classes. So I have to hunt for training points on lesser utilized classes. And they are lesser utilized for a reason. This slows down the overall progress of the project as it takes time to claw for examples of these points.
CUE THE PONZI SCHEME
This is when I came up with an idea. The NLP model reads the raw data and makes a classification effort for 18 different categories. Each category could relate to anywhere from 1 to 5 words in the raw data. Those words can be spelt or abbreviated different several ways that all mean the same thing. By swapping the source words with their alternatives, I can inflate the training data. And depending on the amount of alternative words in a single source sentence, that sentence can be transformed as many as 15 times. Now the model not only gets reinforcement training, but exposure to all spelling and abbreviation types.
That approach turned my 36,000 lines into 293,000.
NEXT
So now I need to ponder my processing power problem. My GTX 1070 doesn’t do a terrible job. But the bigger the model gets, the longer it takes to train. A few ways I think I can approach this without buying hardware:
Adjust Training Parameters
Play with the padding / truncation
Clean up the training data
Consolidate the Category with 140+ possible classes
Research
Housing Data by the County
So I’m thinking about moving to Rhode Island and wanted to be able to have some sort of idea how the markets are up there. When is the best time to buy? How is the market growing? Or is it shrinking? How quickly do I need to make a move?
To answer these questions I turned to Python.
A little research, and I really do mean “little”, brought me to Redfin. Redfin has publicly accessible data covering varying topics all across the United States housing market.
The best part is that I can load this data directly into Python without having to download a CSV or Zip File.
url = 'https://redfin-public-data.s3.us-west-2.amazonaws.com/redfin_market_tracker/county_market_tracker.tsv000.gz' National_Data = pd.read_csv(url,compression = 'gzip', sep ='\t', on_bad_lines = 'skip')
That dataset contains market data for counties all across the US since 2012. Given I only care about Rhode Island and any data prior to Covid would be useless, I narrowed the data down to everything after 2021 in the following Rhode Island counties:
Bristol County
Kent County
Newport County
Providence County
From here I have quite a few pieces of data to look at since Redfin tracks 30+ categories per monthly entry. Some categories include Number of New Listings, Pending Listings, Sold, Percent of the market whose price dropped, Number of homes sold above listing, Number of listings off the market within two weeks, Median list price, median sold price, the monthly and yearly averages for those numbers and so on.
So what do I care about? Great question. I’m not quite sure that I know what I’m looking for but I know what interests me and what might give me some ideas. So I created a series of graphs.
New Listings vs. Pending vs. Sold vs. Sold Above List
What does this graph tell me? Well it gives me an idea of how fast the market is moving and its relative demand. If New listings outpace Pending and/or Sold, then it’s a buyers market. Alternatively, if New can;t keep up with Peding/Sold, it’s a sellers market. And if Sold Above List price goes up, then demand is even higher.

Median Sale v Median List Price
Here I can figure out if the Median List Price has some wiggle to it. If the Median Sale price is higher than the list price, there may be more demand in the area. Or the listed price is just a conversation starter. However, if the Median Sale price is lower than the List price, that means the market may be softening and the buyer has more negotiating power. Which would be good to know for the county you are buying in.

Sold Above List v. Price Dropped v. Off Market in Two Weeks
This graph is similar to the first graph in that it tells me the markets strength at current pricing. Are the homes selling for more or less than originally listed for? And how quickly are they moving off the market? Is it above listing and off the market in two weeks? Or is the price dropping and staying on the market?

Finally, in order to make this report useful to me, I automated it to pull at the beginning of each month and to email me personally when it does. I get a curated email for each county giving me insight into how that market is performing and how I might want to enter it.
Sol 10469...
I do kind of miss the ramblings of a madman that I used to do here while reporting and predicting Covid case counts.
I need a space to type out my thoughts while I work on these bigger projects, sans alcohol.
Currently I am monitoring the success rate of a few stock forecasting scripts. Since I started using Python to inform me of good stocks three months ago, I have seen a 27% return. I’ll probably get into more detail on the subject later, but it includes using Python to do a few things.
Read over the last decade+ of data that Yahoo Finance has on the give stocks and create a ML model to predict the next business days closing price. It’s not usually very accurate on the price, but it is fairly good at predicting the direction the stock will go.
Use MACD, RSI, DMA, SMA30, SMA14, SMA30 together to identify buy and sell signals on a daily basis and alert me when the stock enters either signal.
I then get these reports every morning via email.
I’m looking towards improving these approaches and other signals I should look towards.
Python Powered, Data Focused, Twitter Bots!
This twitter account is powered entirely by automatic bots that I created. They comb through several data points that I find interesting and post about them on a weekly schedule. This includes the protein, housing and stock markets. As well as tracking COVID cases and doing some light tweet sentiment analysis.
This allows me to keep an eye on several topics without having to take the time to manually track or update formulas.
Covid-19: 2020 vs 2021
Seeing all the News outlets talk about the ‘sudden’ spike in Covid Cases and the new Variant running around, I got curious and wanted to see where we were last year at this time.
The following charts compare NEW cases on the same dates (and future dates) from 2020 to 2021.
Dotted lines are 2020 to 2021 (March to February)
Solid lines are 2021+ (March and on)

Texas, Massachusetts, New Jersey and Rhode Island

Massachusetts only

New Jersey only

Rhode Island only

Texas only